What are the most colorful khipus? What characteristics do they have, that inform us about color?
A note to the reader. Marcia Ascher invented a series of color codes to describe the khipus. These have since been encoded into the Harvard Khipu Database, by Carrie Brezine, and are used throughout the Khipu Fieldguide. The Brezine Color Chart organizes these colors by color hue and grey-scale intensity.
# Initialize plotlyplotly.offline.init_notebook_mode(connected =False);# Read in the Fieldmark and its associated dataframe and match dictionaryfrom fieldmark_khipu_summary import Fieldmark_Num_Ascher_ColorsaFieldmark = Fieldmark_Num_Ascher_Colors()fieldmark_dataframe = aFieldmark.dataframes[0].dataframeraw_match_dict = aFieldmark.raw_match_dict()
<Figure size 6000x3000 with 0 Axes>
Code
# Plot Significant khipusignificant_khipus = aFieldmark.significant_khipus() significant_values = [raw_match_dict[aKhipuName] for aKhipuName in significant_khipus]significant_df = pd.DataFrame(list(zip(significant_khipus, significant_values)), columns =['KhipuName', 'Value'])fig = px.bar(significant_df, x='KhipuName', y='Value', labels={"KhipuName": "Khipu Name", "Value": "Number of Ascher Colors", }, title=f"Significant Khipu ({len(significant_khipus)}) for Number of Ascher Colors", width=944, height=500).update_layout(showlegend=True).show()
Of the 651 colors, a snapshot of the top 200 colors (a cumulative 98%) is shown below. As expected, the majority of the cords are solid colors - with close to 30% being white!. Mottled colors follow, with barberpoles eventually showing up.
This is the first graph that shows how important white is as a color, followed by browns of various shades, and mottled colors made from browns and white. Barberpoles may be visually arresting, but the frequency count tells us they seldom (< 0.32%) show up in the khipu record.
As you can see the distribution rapidly declines, with a very very long tail. In fact this distribution appears to be a power law, something that often appears in linguistic contexts. A classic example of a linguistic power law distribution is Zipf’s Law whose first use by linguist Herman Zipf was to note that a word’s length in characters was inversely proportional to it’s use in language. In light of Sabine Hyland’s Collata khipu discovery that 17th-18th Century Collata khipus/khipu boards’ colors implied a phonetic letter scheme, this power law distribution makes sense and adds to her argument.
3. Neighboring Colors by Frequency
Obviously khipu color schemes must follow an intent. One common decrypting approach in cryptography is to see frequency of letters and their neigbors to understand where the letter E is. We can do something similar - evaluate what neighboring colors does a given color have. In banded color groups, the neighbor is a similar color, which you would expect. Unexpected, is that in seriated cord groups the same “twinning” happens. As expected from our previous overall frequency analysis, mottled cords show up much more than barberpole cords for solid color neighbors. For example:
A topic, in NLP, is defined as words that “occur together”; for example, khipu, cord, knot, Inka, etc. might be a topic word set that is common in khipu books.
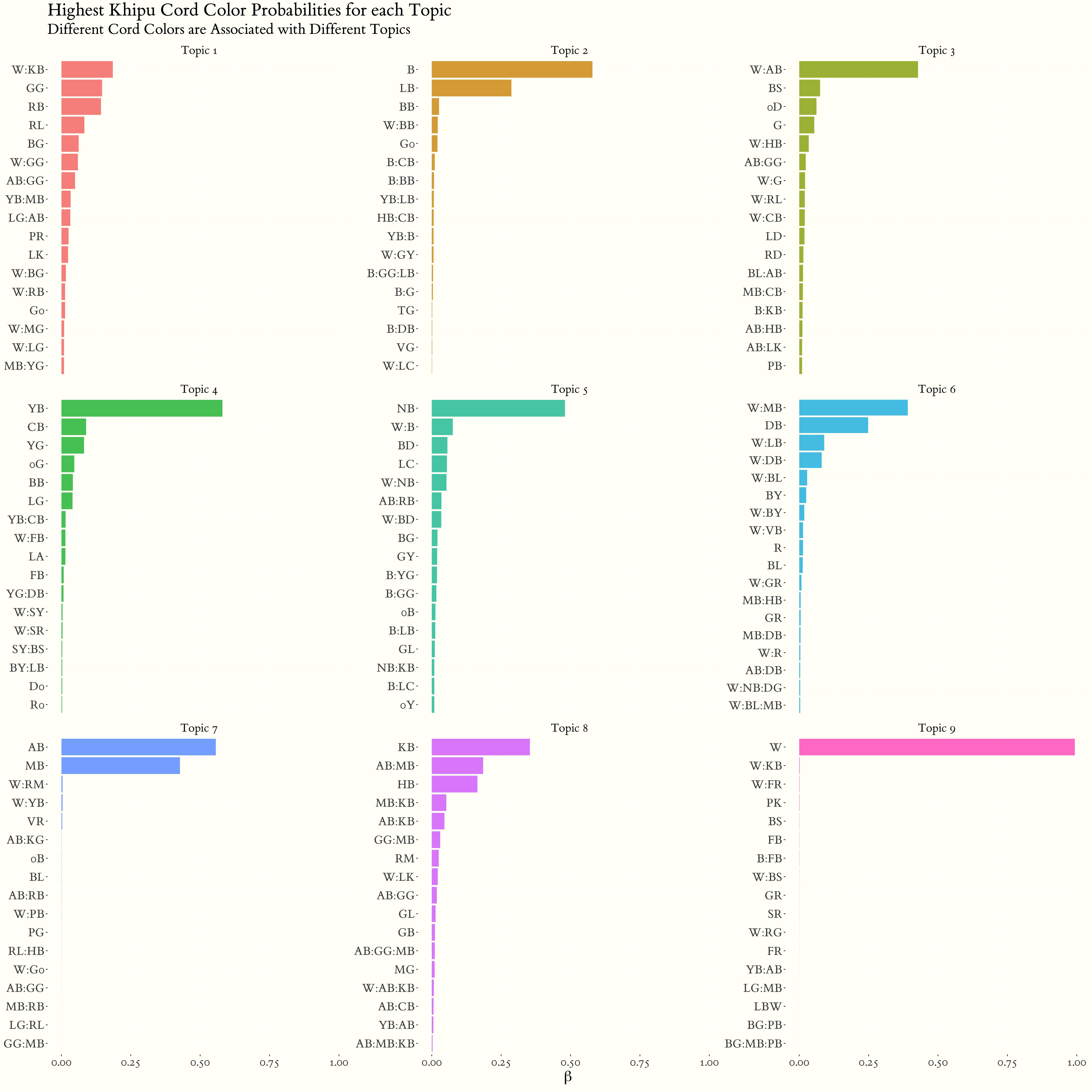
A topic model is a description of a set of topics occurring in a collection of documents. For example, suppose Hemmingway and Jane Austen got together and wrote a novel called A Farewell to Mr. Darcy. We could probably identify two topics in the novel - Jane Austen words, and Hemmingway words. Similarly, we can model colors (and the colors they co-associate with) as “words” in a set of color “topics” that produce a khipu. We can build the probability distributions of words, and then model khipus based on this type of distribution. Building off of the tradition of probabilistic topic models such as the Latent Dirichlet Allocation (LDA), a simple journey to R produces this Structural Topic Model graphic - a teaser of how color is used to construct a khipu. The idea is that documents consist of various “subjects” (ie. topics) and topics consist of various common words (ie. Khipu Cord Colors). In this “sense”, similar to other dimensionality manipulation algorithms such as SVD, etc., topics comprise the “eigen-vectors” of color that create a Khipu.
# From the R Studio environment:
library(tidytext)
library(quanteda)
library(stm)
khipu_docs = read.csv("./data/khipu_docstrings.csv")
khipu_names = khipu_docs$name
khipu_colors = khipu_docs$pendant_color_document
tidy_khipus <- tibble(name=khipu_names, text=khipu_colors) %>%
mutate(line = row_number()) %>%
unnest_tokens(word, text, toupper=FALSE)
khipus_tf_idf <- tidy_khipus %>%
count(name, word, sort = TRUE) %>%
bind_tf_idf(word, name, n) %>%
arrange(-tf_idf) %>%
group_by(name) %>%
top_n(17) %>%
ungroup
khipu_dfm <- tidy_khipus %>%
count(name, word, sort = TRUE) %>%
cast_dfm(name, word, n)
topic_model <- stm(khipu_dfm, K = 9, verbose = FALSE, init.type = "Spectral")
td_beta_topics <- tidy(topic_model) %>%
group_by(topic) %>%
top_n(17, beta) %>%
ungroup() %>%
mutate(topic = paste0("Topic ", topic),
term = reorder_within(term, beta, topic))
td_beta_topics %>%
ggplot(aes(term, beta, fill = as.factor(topic))) +
geom_col(alpha = 0.8, show.legend = FALSE) +
facet_wrap(~ topic, scales = "free_y") +
coord_flip() +
scale_x_reordered() +
labs(x = NULL, y = expression(beta),
title = "Highest Khipu Cord Color Probabilities for each Topic",
subtitle = "Different Cord Colors are Associated with Different Topics")
These are the 9 most common topics made of “word sets”, or as we call them, Cord Colors. A given khipu, then might contain 20% of Topic 4 (mostly YB cords), and 40% Topic 9 (W Cords), etc. Another sample inference; if it contains a lot of Topic 7, there’s a good chance it will have both AB and MB cords in it.
5. Neighboring Group Colors by Frequency and Likelihood
Another way of viewing neighboring group colors is to see which cord group color sequences are most common, either by popularity (i.e. single white cords, then single brown cords, etc.) or by sequence (i.e. one white cord, then white cord, and a brown cord, etc.) - the latter equivalent to a Markov chain matrix, the former, a Bayesian frequentist point of view.
5628 groups exist - The largest has 160 cords.
Out of the 5628 groups, there are 2354 unique sequences.
Only 413 sequences occur 2 or more times.
Let’s view the distribution:
Code
# Khipu Importsimport khipu_kamayuq as kamayuq # A Khipu Maker is known (in Quechua) as a Khipu Kamayuqimport khipu_qollqa as kqimport khipu_utils as kufrom ascher_group_color_frequency import count_most_common_group_colors(color_rep_sorted_frequency, color_rep_sorted_markov) = count_most_common_group_colors()color_rep_frequency_width = [(color_string, count, len(color_string.split(" "))) for (color_string, count) in color_rep_sorted_frequency]df = pd.DataFrame(color_rep_frequency_width, columns = ['color_string', 'count', 'num_colors'])df.head(10)df.tail(10)
color_string
count
num_colors
0
W
628
1
1
PK
368
1
2
AB
312
1
3
LK
291
1
4
W W W W W W
149
6
5
W W W W W W W
137
7
6
DB
125
1
7
W W W
106
3
8
MB
106
1
9
YB
97
1
color_string
count
num_colors
403
W:MB AB
2
2
404
YG
2
1
405
LA
2
1
406
W:B
2
1
407
PB
2
1
408
D0
2
1
409
G
2
1
410
W:YB
2
1
411
W%MB
2
1
412
RL
2
1
You can see that White cords occur A LOT. 4 of the top 5, are White cord groups of (num_cords, count) [1:632, 6:149, 7:137, 3:109, etc…]. At the bottom of the distribution, there are a lot of sequences that only occur twice:
Code
# Initialize plotlyplotly.offline.init_notebook_mode(connected =False);fig = px.histogram(df, x="count", color="num_colors", marginal="rug", log_y =True,# can be `box`, `violin`, hover_data=df.columns, labels={"count": "Number of occurrences of a particular color sequence" }, color_discrete_sequence=px.colors.qualitative.G10, title ="Counts of (log_y), Counts of Unique Group Color-Sequences", width=944, height=950)fig.show()
What exactly is a color-banded group? It’s not a group made from physically knotting cords together into one giant group. On some khipus it’s a series of one cord groups. On others it’s a series of cords inside one group, sometimes even spanning to another cord group.
I decided to define a color-banded group by looking at contiguous pendant colors, regardless of cord group boundaries. What about cords that have multiple ascher colors per cord (i.e. they are segmented cords)? This wrinkle made writing the code a nightmare. I had two apparent solutions. I could define these segmented cords as one concatenated color (ie. a super color), or I could define them by the color of the longest segment. I chose the later for this study. Is this a good and appropriate simplification? It turns out ~3.5% of the pendant cords are segmented colors with a distribution of 1122 out of 32395 cords (3.46%) with (num_color_segments, num_cords) = [(2, 863), (3, 207), (4, 50), (5, 2)]. So, the result is a list of pendant cords independent of cord group limits, arranged by distance along the primary cord, assuming segmented cords use their longest color.
A preview of the resulting search is shown here (click on the image for the full page):
The results are fascinating - especially for white. Of most interest is the preponderance of 6 and 10 cord banded groups, and their half-widths, 3 and 5 - the numbers associated with Inkan ayllus. I think this study indicates that presence of color bands of widths 3,5,6 and 10 indicates a FIELDMARK in the classic sense of characterizing a khipu.
Note also that GG, Grey-Green cords, the 15th highest ranking color, is almost completely missing in banded groups (one occurrence of two GG neighboring cords occurs in the entire KDB). This presence or absence of a GG cord may also constitute a FIELDMARK of some sort.
Further Study
More study of white bands and their locations is indicated, as is an image quilt of banded khipus by the ten to fifteen most common band colors (White, and all values of Browns and mottled white browns).
7. Seriated Color Sequences
We can do a similar search for seriated color sequences. What should we look for? I use the same approach as color-banded groups, but here:
I respect group boundaries
I drop out all banded groups
One thing that becomes apparent in this study is intriguing sequences that start with white. The most common seriated color sequences in cord groups are ones that start or end with white, or have some variant of brown. Also the length of sequences are often Ayllu lengths (6 and 3,5) or a White cord plus Ayllu lengths (i.e. 7)
White cords seem to occupy a special case in the khipu pantheon of colors. A separate page is devoted to the Study of White Cords.
9. Conclusions
Of the 651 colors, the top 200 colors cumulate to 98% of the cords. As expected, the majority of the cords are solid colors - with close to 30% being white!. Mottled colors follow, with barberpoles eventually showing up.
White is the most prevalent color, followed by browns of various shades, and mottled colors made from browns and white.
Barberpoles may be visually arresting, but the frequency count tells us they seldom (< 0.32%) show up in the khipu record.
Cord color frequency distribution rapidly declines, with a very very long tail. In fact this distribution appears to be a power law, something that often appears in linguistic contexts. A classic example of a linguistic power law distribution is Zipf’s Law whose first use by linguist Herman Zipf was to note that a word’s length in characters was inversely proportional to it’s use in language. In light of Sabine Hyland’s Collata khipu discovery that 17th-18th Century Collata khipus/khipu boards’ colors implied a phonetic letter scheme, this power law distribution makes sense and adds to her argument. However, when we look at the actual Zipfian distribution, we see that while it is a power curve, it is not a natural Zipfian distribution. Furthermore, cord colors lack the conventional amounts of hapax legomena the only-once-occuring “words” that comprise 40-60% of the words in natural language.
While white cords comprise a third of all pendant cords, and of cord groups of white, we don’t yet know what their color significance is. One theory, that they are grammatical markers for addition, appears disproved. However, they do show interesting levels of positional significance, appearing at the end or beginning of cord groups that contain many sums (sum groups), and in certain spikes in larger groups (i.e. in odd positions more than even ones).